-

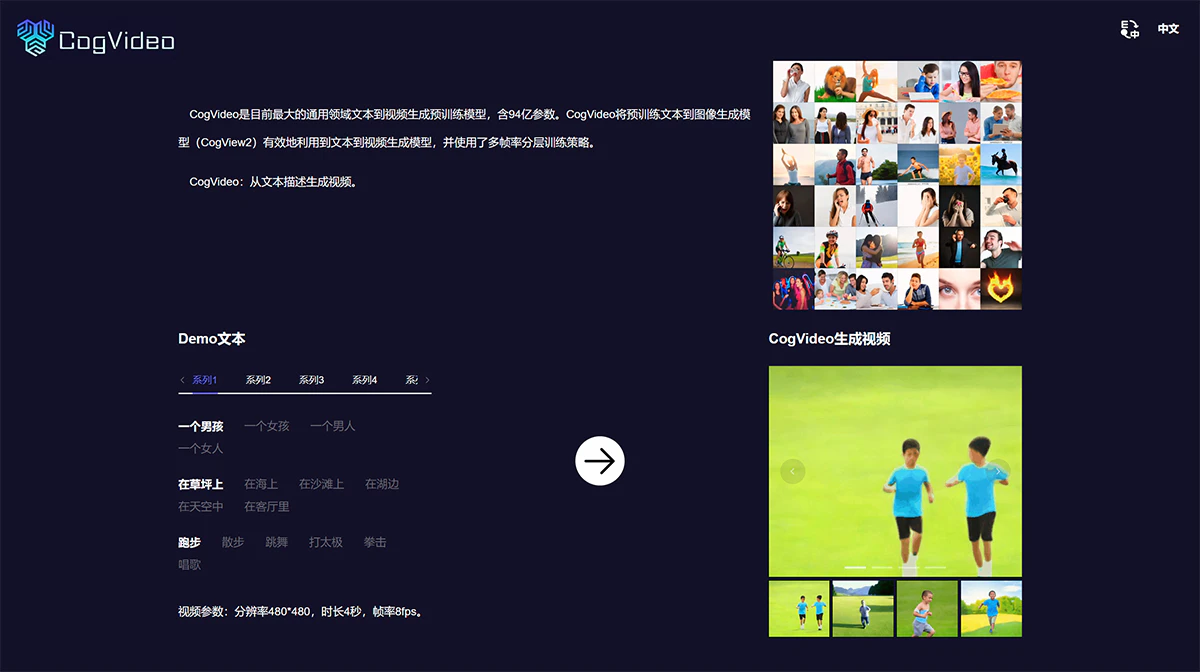
- 文本转视频ai文生视频视频模型CogVideoCogVideo是由智谱 AI 联合清华大学开发的一种开源文本到视频生成模型,基于 Transformer 架构,是一个 94 亿参数的Transformer模型。它通过继承预训练的文本到图像模型 CogView2,并在此基础上进行扩展和训练。


请按 Ctrl+D 收藏本页到浏览器收藏夹回家不迷路!
CogVideo是由智谱 AI 联合清华大学开发的一种开源文本到视频生成模型,基于 Transformer 架构,是一个 94 亿参数的 Transformer 模型。它通过继承预训练的文本到图像模型 CogView2,并在此基础上进行扩展和训练。
技术特点
- 多帧率分层训练:CogVideo 使用多帧率分层训练方法,通过将视频帧标记为图像标记,并结合帧速率标记来调节帧的生成,确保文本与视频之间的对齐。
- 双通道注意力机制:在每个 Transformer 层中,CogVideo 添加了时间注意力通道,用于分析不同帧之间的时间关系,同时继承自 CogView2 的空间注意力机制用于分析每一帧的空间特征。
- 3D 变分自编码器(3D VAE):在 CogVideo 的升级版 CogVideoX 中,采用了 3D VAE 技术,将视频数据压缩至原来的 2%,降低了计算资源需求,同时保持了视频帧之间的连贯性。
- 3D 旋转位置编码(3D RoPE):用于提升时间维度上的连贯性,帮助模型更好地捕捉帧间关系。
性能表现
- 视频质量:CogVideo 能够生成 480×480 分辨率的视频。其升级版 CogVideoX-2B 支持 6 秒、8 帧/秒、720×480 分辨率的视频,而最新的 CogVideoX-5B 则支持更高分辨率和帧率的视频生成。
- 生成速度:CogVideoX 能在 30 秒内生成 6 秒的视频。
如何使用
- 硬件要求:推荐使用 NVIDIA GPU,至少需要 4GB VRAM。如果进行多 GPU 推理,建议每个 GPU 至少有 10GB VRAM。
- 软件依赖:需要安装 Python 3.8 或更高版本、PyTorch 1.10 或更高版本、CUDA 11.3 或更高版本(如果使用 NVIDIA GPU),以及
diffusers库。可以通过以下命令安装这些依赖项:pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113 pip install diffusers
- 下载模型:从 Hugging Face 下载 CogVideoX-2B 模型,访问以下链接: https://huggingface.co/THUDM/CogVideoX-2b
- 加载模型:使用 diffusers库加载模型。
生成视频:通过输入文本描述生成视频。示例代码如下:from diffusers import DiffusionPipeline model = DiffusionPipeline.from_pretrained("THUDM/CogVideoX-2b") model.save_pretrained("./cogvideox-2b")prompt = "A cat playing with a ball of yarn" video = model(prompt).videos video.save("output.mp4")
- 参数调整:可以调整以下参数以优化生成效果:
- num_inference_steps:推理步骤数,默认为 50。
- guidance_scale:指导比例,默认为 7.5。
应用场景
CogVideo 及其升级版广泛应用于多个领域,包括:
- 影视创作:快速生成分镜头、特效片段。
- 营销与教育:制作产品演示动画、科普动态图解。
- 社交媒体:生成创意短视频。
- 开发者生态:通过 API 接入,赋能电商、游戏等行业。
数据统计
特别声明&浏览提醒
本网站提供的「CogVideo」相关内容均来源于网络搜集整理,不保证跳转外部链接的准确性和完整性。网站外部链接的内容在[2025-05-25]录入之前合规合法,后期网站的内容如出现违规或者损害了您的利益,可以直接联系网站管理员进行删除。如果涉及到金钱交易,请仔细甄别,避免上当受骗!
 SkyReels-V2和SkyReels-V1相比,
SkyReels-V2和SkyReels-V1相比, Claude 4有什么特点,为什么
Claude 4有什么特点,为什么 Devin与GitHub Copilot相比有哪
Devin与GitHub Copilot相比有哪 MCP是什么?为什么说谁把
MCP是什么?为什么说谁把日榜周榜
AI工具
热门标签
ai创作(14) 虚拟人像(1) 智能体模型(8) ai文生视频(31) ai对话工具(43) 人工智能模型(3) ai聊天(41) CogAgent(1) ai大模型(17) 文本转语音(25) 声音克隆(11) ai翻译工具(18) 语音合成(8) 大语言模型(6) ai编程(27) 智能编码(5) 文档生成(1) 大模型(13) ai语音生成(13) ai开发工具(4) ai论文助手(9) ai视频精修(8) AI编程助手(20) AI添加字幕(1) 自然语言处理(9) ai搜索(11) 智能编程助手(6) 电脑智能体(1) 多模态(18) ai机器人(5)